Building intelligent agents can be easy. Trusting them is another story.
As AI systems become more capable, understanding why they make decisions becomes critical. Yet most evaluation methods still focus on surface metrics like accuracy or latency, leaving behind reasoning quality, data grounding, and decision logic.
To build reliable, enterprise-ready AI systems, we need to go beyond surface performance numbers and start evaluating how well agents reason, plan, and learn.
In this article, we’ll explore an AI evaluation framework for agentic systems, introduce key AI performance metrics, and show how to benchmark and evaluate AI agents using StackAI’s AI observability and analytics dashboards.
Why Evaluating Agentic AI Systems Is Harder Than You Think
Agentic pipelines are non-deterministic.
What does that mean in practice? It means two identical prompts can lead to different reasoning paths, tool choices, or retrieval strategies. That’s why AI benchmarking and reproducibility are harder here than with more traditional AI approaches. Success isn’t only about the final answer—but also about how the agent actually got there.
A truly effective agentic AI evaluation looks beyond surface-level metrics and digs into reasoning quality, decision logic, and data groundedness. We need to ask: Did the agent choose the right tool for the task? Was its plan efficient, or did it take unnecessary steps? Were its outputs backed by the right evidence? These are just some of the questions that define AI trust and reliability.
Moreover, agentic pipelines run across multiple layers, from retrieval and reasoning to generation and orchestration, and each layer introduces potential failure points. Without strong AI observability and a clear AI evaluation framework, you’re left with black-box risks: systems that look intelligent but can’t be trusted when the stakes are high.
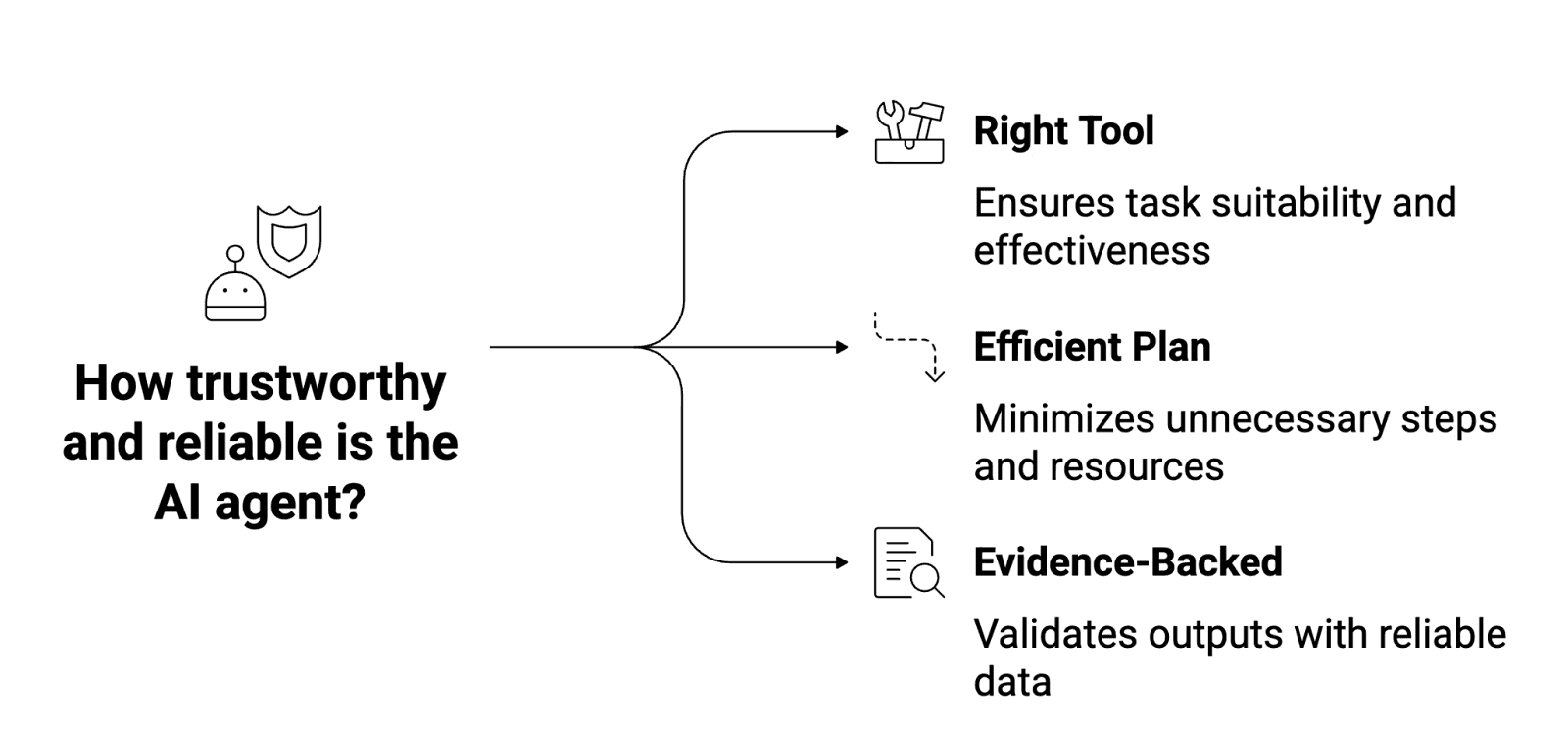
The Core Dimensions of AI Evaluation: Accuracy, Reasoning, and Groundedness
Now that we know traditional accuracy-based testing isn’t enough, the next step is to figure out what really matters when we evaluate AI agents. A good AI evaluation framework should capture not just what an agent outputs, but how it thinks, how it plans, and how it checks the information along the way.
In agentic AI evaluation, that means looking at performance from several angles: accuracy, reasoning, groundedness, efficiency, and user trust.
Dimension | What it Captures | Example metric |
Outcome Quality (Accuracy) | Measures whether the agent achieved the intended result or produced factually correct outputs. | Task success rate, factual precision, relevance score |
Reasoning Quality | Evaluates the logic and coherence behind the agent’s process: how it connects data, plans steps, and makes decisions. | Step validity, reasoning path length and coherence |
Data Groundedness | Assesses how well the agent supports its claims with real evidence from its knowledge base or retrieval sources. | Context relevance, citation quality, hallucination rate |
Operational Efficiency | Captures how effectively the agent balances cost, latency, and resource use without sacrificing quality. | Average response time, token cost, error rate |
Feedback | Combines human judgment and LLM-as-a-judge scoring to quantify helpfulness, tone, and overall user satisfaction. | Rating score, preference comparison, feedback consistency |
Together, these elements form a structured AI performance metrics framework that you can use to benchmark AI agents at every stage, from prototype to production.
AI observability brings it all together. If you keep an eye on how each of these dimensions change over time, you can spot when agents drift off track, see where they’re improving, and build real trust through transparent evaluation.
Used well, these metrics turn evaluation into a measurable and repeatable process—one that helps you understand not just how your agents perform, but how they evolve and respond to different prompts.
The next step is putting that framework into action. With StackAI’s integrated evaluation and observability tools, you can track, benchmark, and refine your AI agents at every stage.
Using StackAI to Benchmark and Evaluate AI Agents
StackAI makes agentic AI evaluation practical. Instead of juggling disconnected tools and manual scripts, you get everything you need for AI benchmarking and AI observability in one place, from tracking performance metrics to evaluating reasoning quality.
🔗 Learn More: If you want to know more what StackAI is, we recommend reading our dedicated articles.
Firstly, in StackAI you can enable citations when working with RAG pipelines with one click. This means every answer your agent produces links directly to the source it came from, which allows you to easily check the accuracy and reliability of its output. It’s an essential part of measuring data groundedness, since you can instantly verify whether responses are supported by the right evidence.
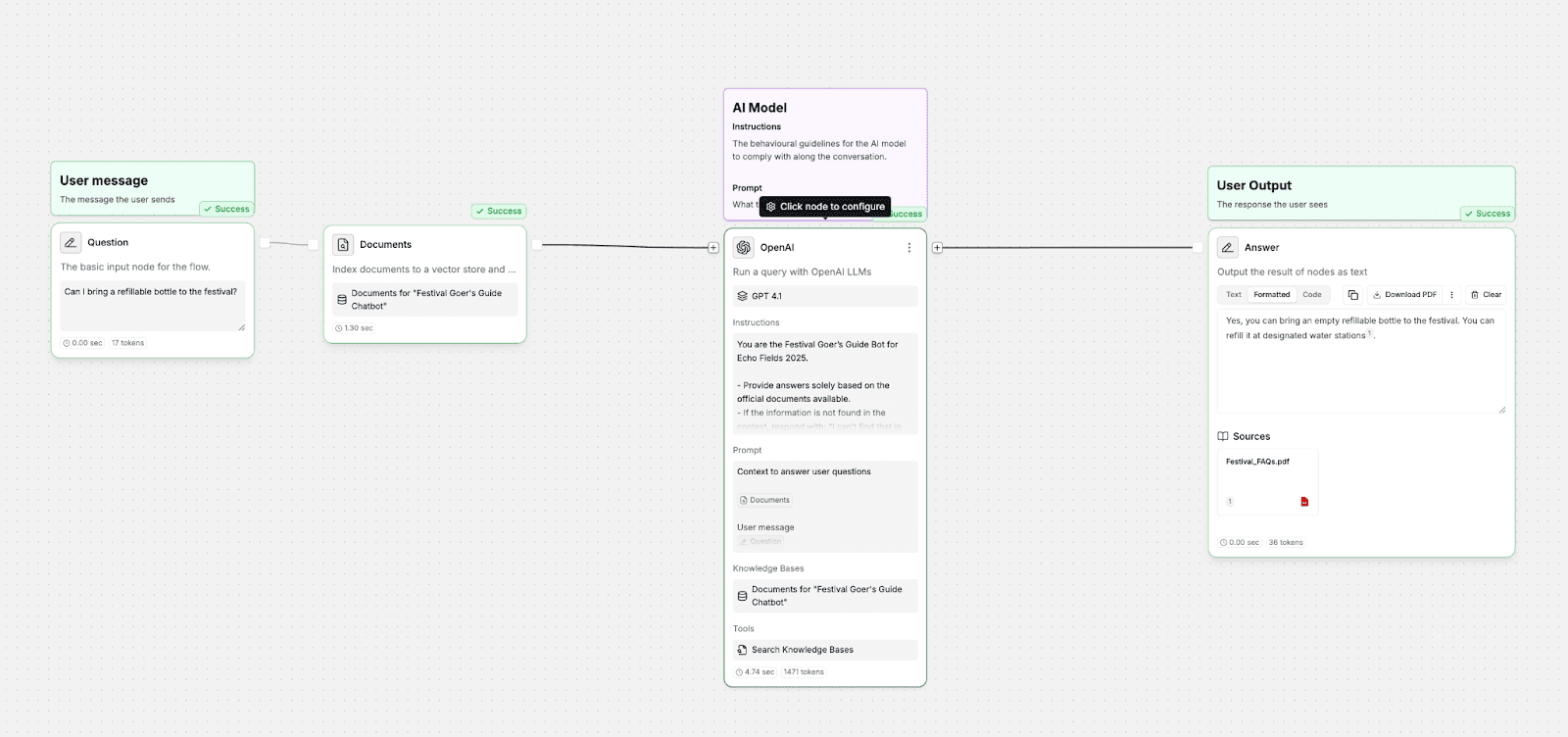
In this example, we’ve built a simple Festival Goer’s Guide Bot in StackAI. The user asks, “Can I bring a refillable bottle to the festival?” The workflow runs through four nodes:
User Message: Captures the question.
Documents: Connects to the uploaded knowledge base and indexes it for retrieval.
AI Model: Runs the query using GPT-4.1.
User Output: Displays the final response.
As you can see in the output panel, the agent answers directly: “Yes, you can bring an empty refillable bottle to the festival…” and cites its source. The reference icon next to the sentence links back to the Festival FAQs.pdf, showing exactly where the information came from.
This built-in citation feature helps you verify accuracy and data groundedness in this type of workflow. You can instantly trace the reasoning behind each answer, confirm the source, and make sure your AI response is based on transparent, verifiable evidence.
You can also see exactly what’s happening behind the scenes when a workflow runs. The interface shows which nodes or tools were used, how data moved through the pipeline, and what decisions the agent made along the way. This level of AI observability helps you understand not just the output, but the process that led to it, so you can spot inefficiencies, dead ends, or retrieval errors that might otherwise go unnoticed.
From there, StackAI offers two complementary views of your agent’s performance: the Analytics Dashboard and the Evaluator Interface.
Analytics Dashboard: Measuring What Matters
Next, the AI analytics dashboard gives you a clear view of your pipeline’s overall health. You can track AI performance metrics like total runs, latency, error rate, token usage, and model versions, all visualised over time. Each execution is logged with full context. It’s a simple way to spot drift, track improvements, and compare versions of your agent workflows side by side.
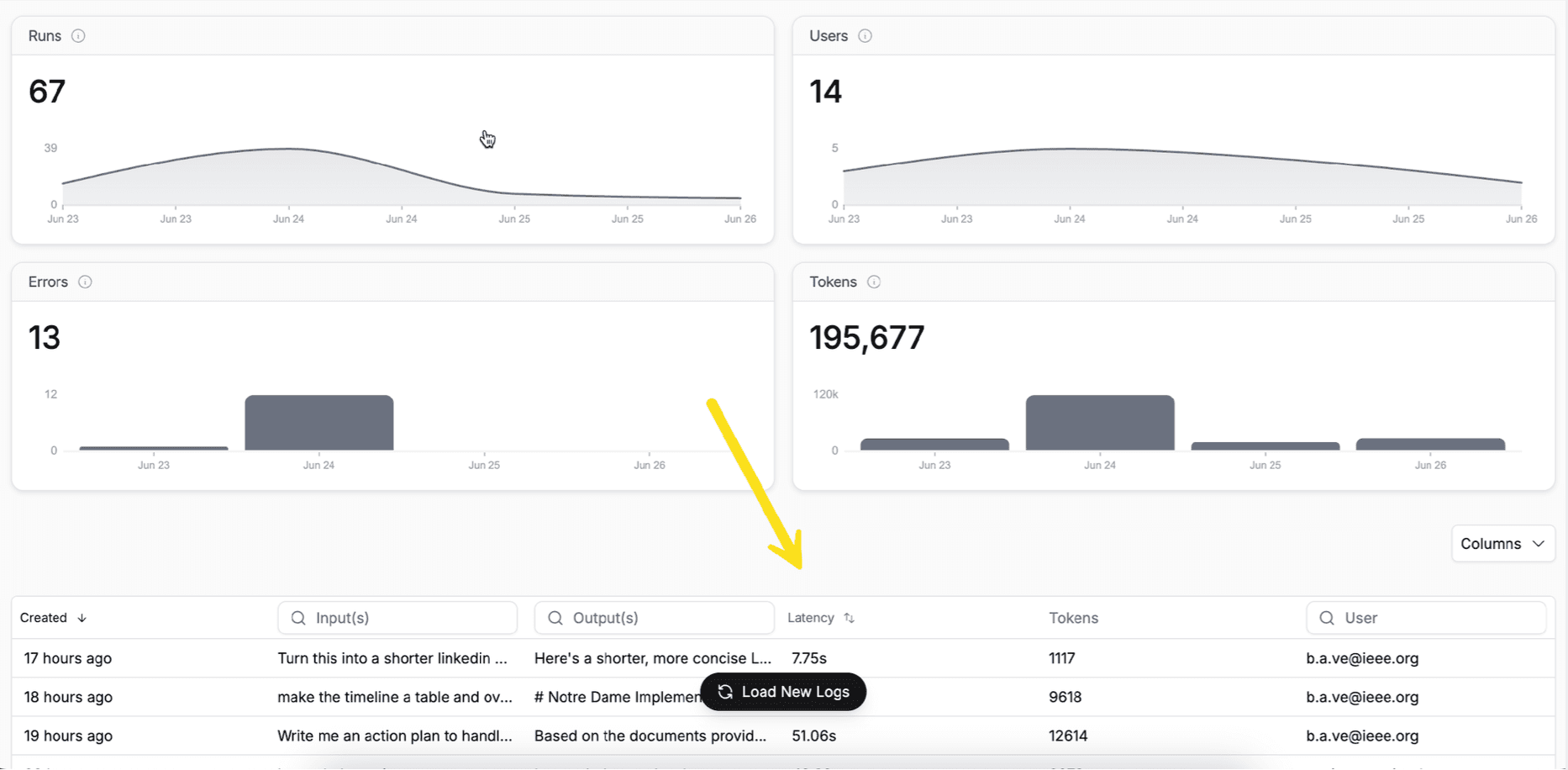
The dashboard tracks several key AI performance metrics:
Runs: The total number of completed executions.
Errors: Any failed runs.
Users: How many unique users interacted with the workflow.
Tokens: Total tokens processed, which helps you monitor cost and efficiency.
At the bottom, you can also inspect each run in detail, including its status, input, output, latency, and model used.
Evaluator Interface: Understanding How Your Agents Think
The Evaluator on StackAI goes a step deeper. You can seamlessly:
Configure an AI evaluation agent.
Write a grading prompt such as “Score this response from 1–10 based on clarity, accuracy, and helpfulness.”
Decide whether to compare outputs against an expected answer for reference-based scoring.
Run batch evaluations across dozens of queries to see patterns in reasoning and quality.
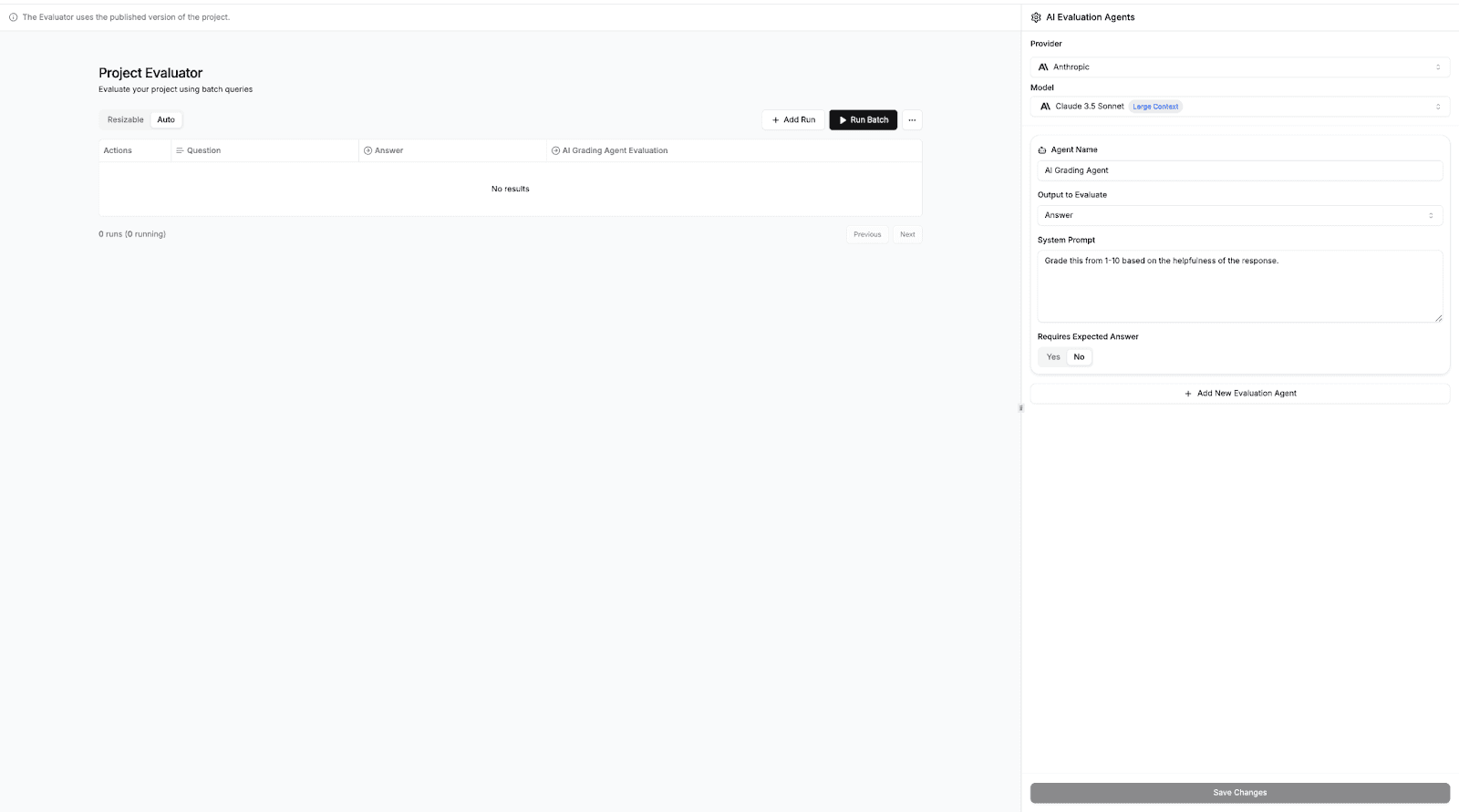
This is how the Evaluator dashboard in StackAI is configured. From here, you can set up an AI grading agent to automatically assess your agent’s outputs.
Choose which output to evaluate, write your own evaluation criteria, and decide whether to compare against an expected answer. Once everything is set up, you can run individual tests or batch evaluations to score multiple outputs at once within the same interface.
Together, these features let you evaluate AI agents from multiple angles without having to leave the StackAI workspace.
LLM-as-a-Judge: AI Evaluation at Scale
LLM-as-a-Judge is a method where a large language model (LLM) reads another model’s output and scores it against clear criteria. This “LLM judge” can assess a wide range of qualities, such as:
Factual accuracy → Is the answer correct and supported by evidence?
Clarity → Is the response easy to follow and well-structured?
Goal alignment → Does it address what the user actually asked for?
Tone and style → Is it appropriate for the context or audience?
Reasoning quality → Does the logic make sense from step to step?
Creativity or usefulness → For open-ended tasks, does it provide original or valuable insight?
This method brings scalability and consistency to agentic AI evaluation. Rather than spending hours manually comparing responses, you can efficiently run batch evaluations across hundreds of examples.
To see how this works in practice, let’s test it with a simple example. We built a basic Workout Planning Agent in StackAI, a small pipeline that generates weekly workout routines based on the user’s availability, time, and goals.
The setup uses just a few essential nodes:
Input Node: So the user can provide details like: “I can train 3 days a week for 45 minutes, and my goal is to build endurance.”
LLM Node: The heart of the pipeline, which creates a workout plan based on the prompt and the system instructions.
Output Node: Displays the generated workout plan for review.
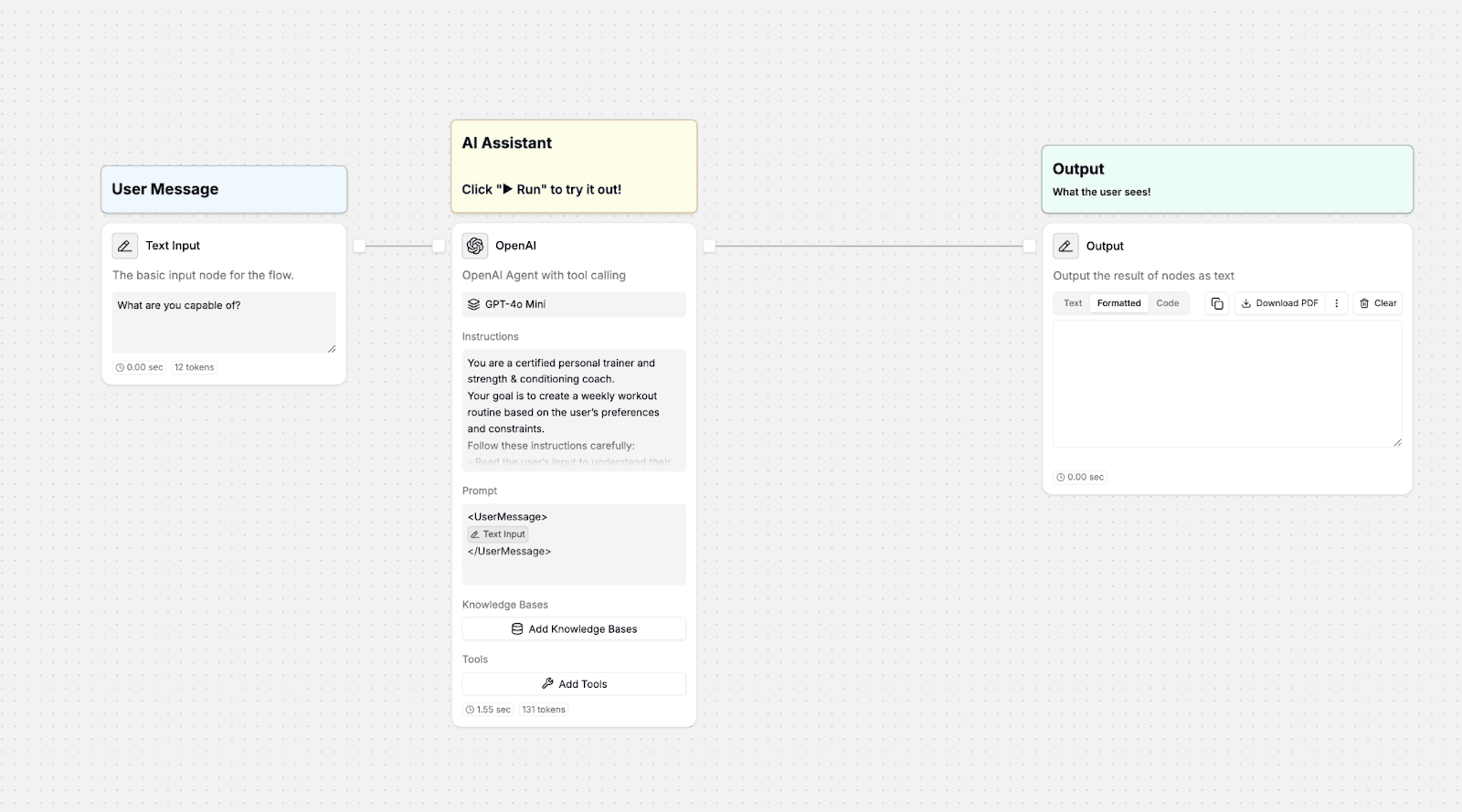
This simple structure will allow us to show how to evaluate reasoning and quality with StackAI’s Evaluation.
Let’s configure the following system prompt for our Personal Trainer Agent:
You are a certified personal trainer and strength & conditioning coach.
Your goal is to create a weekly workout routine based on the user’s preferences and constraints.
Follow these instructions carefully:
Read the user’s input to understand their goal, number of available days, session duration, and any specific preferences or limitations.
Build a balanced weekly plan that includes a mix of strength, endurance, mobility, and recovery sessions, depending on their goal.
Keep each session within the specified time limit.
Clearly label the days, focus areas, and approximate duration for each workout.
If the user’s request is incomplete, make reasonable assumptions and explain them briefly in your answer.
Always prioritize safety, progression, and recovery balance in your recommendations.
Output your response in a structured format such as:
Example Output:
Goal: [User’s Goal]
Weekly Plan:
Day 1: [Workout Type – Duration – Notes]
Day 2: [Workout Type – Duration – Notes]
…
End with a short summary (2–3 sentences) explaining how the plan supports the user’s goal.
Once the agent is built, let’s publish our workflow and move to the evaluator tab. Here we set up an AI judge using Claude 3.5 Sonnet as the model and give it a specific system prompt to guide its scoring:
You are an expert fitness coach and evaluator.
Your task is to review a workout plan created by an AI personal trainer and rate its quality across key dimensions.
Read the user’s request and the AI-generated workout plan, then score the plan for each of the following aspects on a scale from 1 to 10, where 1 = very poor and 10 = excellent.
Scoring Criteria:
Goal alignment: Does the plan match the user’s stated fitness goal (e.g., endurance, strength, mobility, or general fitness)?
Time accuracy: Does each session fit within the time available, and is the total schedule realistic for the user’s stated availability?
Balance: Does the plan distribute workouts sensibly across the week, balancing muscle groups, rest days, and exercise types?
Clarity: Is the plan clearly structured and easy to follow, with clear labelling of days, durations, and workout types?
Safety and progression: Does the plan encourage safe, progressive training without overloading the user?
For each criterion, provide:
A score from 1–10
A short comment (1–2 sentences) explaining your reasoning.
Finally, calculate the average score across all five aspects and include it at the end.
Now we’re going to try different user inputs. We’ll keep them varied in goal and availability so we get a good spread of responses for the evaluator to score.
Strength and Conditioning Focus: I want to build full-body strength and muscle tone. I can train 4 days a week for 60 minutes per session. I have access to a gym with weights.
Mobility and Recovery Emphasis: I’ve been feeling tight from sitting all day and want to improve mobility and posture. I can train 3 days a week for 30 minutes each session. No gym, just a yoga mat at home.
Endurance Training Goal: I’m training for a half marathon in 12 weeks. I can train 5 days a week for 45 minutes. Please include both running and cross-training sessions.
Busy Schedule, General Fitness: I just want to stay active and healthy. I can only train 3 days a week for 25 minutes. I prefer bodyweight exercises and short sessions I can do at home.
Fat Loss and Conditioning: I want to lose fat and improve stamina. I can train 6 days a week for 40 minutes each. I like a mix of cardio and strength, and I’m okay with gym equipment.
These are the responses and evaluations that we get:


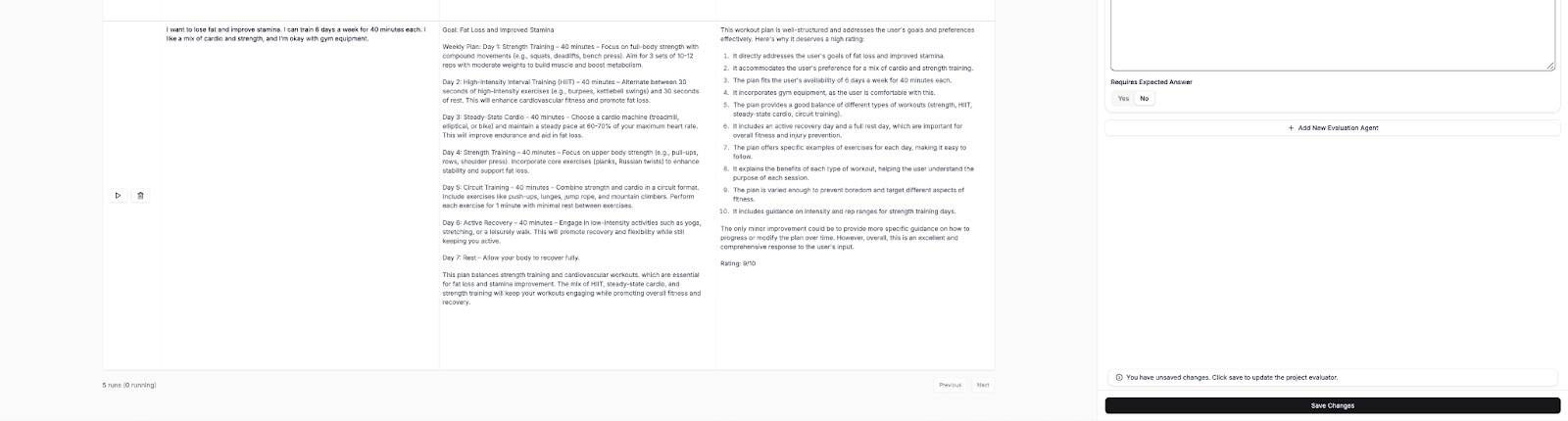
In this table, we can see how the LLM-as-a-Judge evaluates each workout plan created by the agent. Each user input (on the left) corresponds to a generated workout plan (in the center), followed by the AI Grading Agent’s evaluation (on the right).
For every plan, the evaluator reads the AI-generated output and scores it against the five predefined criteria from the system prompt: goal alignment, time accuracy, balance, clarity, and safety and progression.
The evaluator provides a short written explanation for each criterion, then calculates an overall grade (for example, 8/10 or 9/10) that reflects the average of the five scores. You can see how it justifies each rating with concrete reasoning, such as noting strong structure, clear labelling, or areas where the plan could include more progression guidance.
This is where LLM-as-a-Judge shows its strength: it delivers detailed, consistent feedback across multiple runs, something that would be time-consuming to do manually. The results are automatically stored in the StackAI Evaluator interface, so you can compare responses side by side and quickly spot patterns in quality and reasoning.
🔗 Learn More: If you want to know more about building your own chatbots, we recommend reading our dedicated articles.
Conclusion: From Evaluation to Evolution
Evaluation isn’t just the final step in building AI agents but the foundation for improving them. As systems become more agentic, with the ability to reason, plan, and act independently, AI evaluation becomes the key to maintaining trust, transparency, and reliability.
With StackAI, you can close the feedback loop: design, test, measure, and refine, all in one place where the combination of AI observability, AI benchmarking, and LLM-as-a-Judge scoring turns abstract intelligence into something tangible and trackable.
Want to see the evaluator in action at your enterprise? Book a demo today.

Ana Rojo-Echeburúa
Growth at StackAI

